Specific Criticism of CVSS4
Marc Ruef


Die Grundlage bestehender Computersicherheit wird durch die Eingabeprüfung geschaffen. Bei dieser werden frühstmöglich die Eingaben durch die Applikation validiert, um unerwünschte und unerwartete Abweichungen feststellen und auf sie reagieren zu können. In diesem Artikel werden die Grundlagen moderner, effizienter und eleganter Eingabeprüfung im Detail diskutiert. Angehende und erfahrene Entwickler können dadurch ihr Wissen verbessern, um sichere Anwendungen schreiben zu können.
Angewandte Computersicherheit im Allgemeinen und Softwaresicherheit im Speziellen sind in erster Linie von einer Eigenschaft abhängig: Der Eingabeüberprüfung. Die von einem System entgegengenommenen Daten müssen frühstmöglich, mindstens vor der effektiven Weiterverarbeitung im allgemeinen Programmzyklus, auf ihre Richtigkeit hin geprüft werden. Nur durch diese Validierung kann erkannt werden, ob der weiterführende Prozess den besonderen und eventuell unerwarteten Eigenschaften der Daten gerecht werden kann. Ist dem nicht so, sollte oder muss von einer weiteren Nutzung der damit als infiziert erkannten Daten, in der englischsprachigen Literatur werden sie infected genannt, abgesehen werden.
Eine Eingabeüberprüfung kann innerhalb der Applikation durch verschiedene Techniken realisiert werden. In dieser Abhandlung sollen anhand funktionierender Programmbeispiele aufgezeigt werden, welche Ansätze verfolgt werden können und welche Vor- sowie Nachteile sie mit sich bringen.
Die Grundlage der weiterführenden Diskussion ist die allgemeine Funktionsweise einer Eingabeüberprüfung. Einführend soll mit der abgedruckten Anwendung application.php, sie besteht lediglich aus 9 Codezeilen, die jeweiligen Beispiele erarbeitet werden:
$notvalidated_input = $_GET['user_input'];
if(isinfected($notvalidated_input)){
echo 'Input infected: Abort!';
exit;
}else{
echo 'Input okay: Execute...';
dosomething();
}Hierbei handelt es sich um eine Webapplikation, welche in Zeile 01 die Eingabe der GET-Anfrage aus $_GET['user_input'] in die Variable $notvalidated_input speichert. Wie die Namensgebung erahnen lässt, sind die Ursprungsdaten durch den Benutzer definiert worden (user_input) und werden in die noch nicht geprüfte Variable (notvalidated_input) abgelegt.
Sofort nach der Entgegennahme der Eingaben soll eine Prüfung auf diese angewendet werden. Hierzu kommt die noch nicht weiter diskutierte Funktion isinfected() in Zeile 03 zum Tragen. Ihr wird als erstes und einziges Argument die noch nicht geprüfte Variable $notvalidated_input übergeben.
Liefert dieser Funktionsaufruf true zurück, entscheidet die bedingte Anweisung if, dass die Programmausführung in Zeile 04 weitergefahren wird. Dabei wird durch echo die Fehlermeldung Input infected: Abort! ausgegeben und das Programm in Zeile 05 mit exit sofort verlassen. Da die Eingabe infiziert schien, wird also auf eine weitere Ausführung gänzlich verzichtet.
Liefert die Eingabeüberprüfung hingegen ein false zurück, wird stattdessen der else-Block ab Zeile 06 ausgeführt. Dabei wird exemplarisch in Zeile 07 die Meldung Input okay: Execute... dargestellt. Die weitere Programmausführung wird durch die nicht weiter beschriebene Funktion dosomething() in Zeile 08, sie könnte eine Datenbankabfrage mittels SQL durchführen, symbolisiert.
Es soll sich von nun an auf die zentrale Funktion isinfected(), welche für die Eingabeüberprüfung zuständig ist, konzentriert werden. Verschiedene Implementierung dieser, welche massgeblich für die Sicherheit der gezeigten Anwendung verantwortlich sind, sollen behandelt werden. Schliesslich führt sie die Eingabeprüfung durch und beeinflusst in zentraler Weise die Entscheidung, ob der reguläre Programmfluss verfolgt werden will oder nicht.
Es handelt sich hier also um eine eigens geschriebene Funktion, die so nicht in der eingesetzten Programmiersprache angeboten wird. Wir können die Eigenschaften der Funktion damit selbst bestimmen. Als Eingabe werden in erster Linie prüfende Daten erwartet. Dies können interne Variablen, Rückgabewerte von Datenbanken, benutzerdefinierte GET-/POST-Variablen oder Daten von Webformularen sein. Der Aufruf von isinfected($value) führt also dazu, dass die Funktion isinfected() die Variable $value validiert.
Konnte die Eingabeüberprüfung einen unerwünschten Zustand feststellen, liefert isinfected() den boolschen Wert true (wahr) zurück. In diesem Fall weiss das Hauptprogramm, dass die geprüften Daten infiziert sind und von einer weiteren Nutzung bzw. Ausführung abgesehen werden sollte. Konnte hingegen keine potentielle Unsicherheit festgestellt werden, liefert die Funktion den boolschen Wert false (falsch) zurück. Der Nutzung der Daten steht also, vertraut man denn der Prüfung, nichts mehr im Weg. Selbstverständlich könnte eine andere Implementierung von isinfected() anstelle von true/false auch die Integerwerte 1/0 oder Zeichenketten wie Unsicher/Infiziert zurückliefern. Der Einfachheit halber und zu Gunsten der Ausführungsgeschwindigkeit wird hier jedoch auf boolsche Werte gesetzt.
Das erste Beispiel einer Implementierung von isinfected() nutzt die strengste Form der Prüfung. Hierbei wird ein absoluter Vergleich im Rahmen einer Whitelist durchgeführt. Hierzu werden die klassischen Vergleichsoperatoren, wie sie in den meisten Programmiersprachen ohnehin angeboten werden, herangezogen:
function isinfected($notvalidated_input){
if($notvalidated_input == 'name'){
return false;
}else{
return true;
}
}Diese Implementierung namens whitelist_strong.php umfasst lediglich 7 Zeilen. Direkt zu Beginn wird der Inhalt der übergebenen und in $notvalidated_input abgegebenen Variable mittels dem Vergleichsoperator == daraufhin überprüft, ob sie der Zeichenkette “name” entspricht (Zeile 02). Ist dies der Fall, ist die Eingabe geprüft und erlaubt. Die Funktion liefert sodann mittels dem Aufruf return den Wert false zurück und wird beendet (Zeile 03).
Ist in $notvalidated_input hingegen nicht der erwartete Wert “name” enthalten, wird der Wert true zurückgegeben und die Funktion beendet (Zeile 05). Man spricht hier von einer sogenannten Whitelist. Die bedingte Anweisung prüft nämlich anhand einer Liste, sie enthält in diesem Beispiel nur einen Eintrag, ob die Eingabe zugelassen ist. Man kann dies mit einer Gästeliste für eine exklusive Party vergleichen: Ist der Name eines Gasts nicht auf der Liste enthalten, wird ihm der Zutritt zum begehrten Anlass verwehrt.
Dieses Verfahren gilt als das Sicherste. Denn schliesslich muss eine zu jedem Zeitpunkt nachvollziehbare Situation vorherrschen, damit die Weiterführung erlaubt wird. Ist diese Situation nicht gegeben, hat man es mit etwas Unerwartetem und potentiell gefährlichem zu tun. Dies führt zwar dazu, dass vielleicht auch Gästen der Zutritt zur Party verwehrt bleibt, obschon sie eigentlich angenehme Gesprächspartner gewesen wären. Sicherheit geht hierbei jedoch vor. Eine jede hochsichere Anwendung sollte auf eine solch strinkte Implementierung einer Eingabeüberprüfung setzen.
In einigen Fällen, wie zum Beispiel bei Formularfeldern, ist es durchaus möglich, dass die Whitelist um die erwarteten Werte erweitert werden. In whitelist_form.php wird das zuvor genannte Beispiel mit der Zeichenkette name durch die zusätzlichen Felder address (Zeilen 04-05), phone (Zeilen 06-07) und mail (Zeilen 08-09) ergänzt. Wird einer dieser Werte beobachtet, ist er erlaubt und die Funktion liefert sinngemäss false zurück. Handelt es sich jedoch um eine andere und damit unerwartete Eingabe, wird wie üblich der Wert true zurückgegeben (Zeilen 10-11):
function isinfected($notvalidated_input){
if($notvalidated_input == 'name'){
return false;
}elseif($notvalidated_input == 'address'){
return false;
}elseif($notvalidated_input == 'phone'){
return false;
}elseif($notvalidated_input == 'mail'){
return false;
}else{
return true;
}
}Es gibt Situationen, in denen ist es nicht tragbar, dass unbekannte Eingaben einfachso als infiziert deklariert werden können. Gerade bei Daten, die eine sehr komplexe und unvorhersehbare Struktur aufweisen, ist dies der Fall. Bestes Beispiel ist das Eingabefeld eines Webforums, in dem die jeweiligen Benutzer ihre Postings nach Belieben verfassen können. Es ist unmöglich innerhalb einer Whitelist zu definieren, welche Posts erwartet und erlaubt sind. Dazu müsste theoretisch jedes mögliche Posting bekannt und in der Whitelist abgespeichert werden. Je nach unterstütztem Zeichensatz und erlaubter Posting-Länge wären dies mehrere millionen Milliarden Whitelist-Einträge.
In solchen Fällen wird auf den umgekehrten Ansatz der Blacklists zurückgegriffen. Auf einer solchen schwarzen Liste sind sämtliche Eingaben vermerkt, die definitiv nicht zugelassen werden, da deren Gefährlichkeit bekannt ist. Meistens handelt es sich dabei um üblicherweise innerhalb spezifischer Attacken genutzte Muster. Man spricht hier deshalb auch von einem pattern-basierten Ansatz. In blacklist_form.php wird die Eingabe daraufhin geprüft, ob sie den Zeichenketten /etc/passswd (Zeile 02) oder /var/log/messages (Zeile 04) entspricht. Ist dem so, also die Eingabe gleich dem Blacklist-Wert, wird er nicht zugelassen und true zurückgegeben (Zeile 03 oder 05). In allen anderen Fällen, in denen also keiner der zwei gelisteten Werte gegeben ist, wird keine Infektion erwartet und damit false geliefert (Zeilen 06-07):
function isinfected($notvalidated_input){
if($notvalidated_input == '/etc/passswd'){
return true;
}elseif($notvalidated_input == '/var/log/messages'){
return true;
}else{
return false;
}
}Dieser Ansatz weist verschiedene Probleme bezüglich Administration und Sicherheit auf. Je grösser die Blacklist wird, desto umfangreicher wird die Funktion. Schliesslich muss für jeden unerwünschten Wert eine neue bedingte Anweisung eingeführt werden. Im genannten Beispiel werden zwei wichtige Systempfade aufgelistet. Möchte man nun sämtliche dieser abdecken, müssten Duzende eingeführt werden. Die Funktion wächst damit auf mehrere Hundert Zeilen an. Hierbei den Überblick zu wahren ist fast nicht mehr möglich. Um die Programmlogik von den Nutzdaten zu trennen, wird das mit blacklist_infile.php illustrierte Modell vorgeschlagen:
function isinfected($notvalidated_input){
$disallowedstrings = file('blacklist.txt');
if(in_array($notvalidated_input, $disallowedstrings)){
return true;
}
}Hierbei wird eine Textdatei mit sämtlichen Blacklist-Einträgen angefertigt. Diese Datei namens blacklist.txt wird in Zeile 02 durch die Funktion file() eingelesen. Hierbei wird jede Zeile der genannten Datei in das Array $disallowedstrings übertragen. In der ersten Zeile von blacklist.txt findet sich also /etc/passwd, was in $disallowedstrings[0] abgelegt wird und in der zweiten Zeile findet sich /var/log/messages, was in $disallowedstrings[1] abgelegt wird.
In Zeile 04 findet nun eine Prüfung statt, ob die übergebene Eingabe $notvalidated_input einen der im Array $disallowedstrings gespeicherten Werte enthält. Hierzu wird die Funktion in_array() genutzt, welche als ersten Parameter den Haystack (Wo soll gesucht werden?) und als zweiten Parameter die Needle (Was soll gesucht werden?) erwartet. Wird einer der Werte in Zeile 04 gefunden, wird eine Infektion durch die Blacklist erkannt, der Wert true zurückgeliefert und die Funktion verlassen. In allen anderen Fällen kann keine Infektion festgestellt werden und deshalb wird standardmässig false zurückgegeben. Die eigentliche Funktion bleibt mit 7 Zeilen sehr klein und die Blacklist kann unabhängig dieser in der übersichtlichen Textdatei (sie wird eventuell gar durch eine relationale Datenbank geschrieben) moderiert werden.
Um zu verhindern, dass ein Angreifer durch das Auslesen der Blacklist-Datei neue Strategien zum Umgehen dieser ausarbeiten kann, sollte sie nicht öffentlich zugänglich sein (z.B. durch .htaccess geschützt oder in nicht-öffentlichem Verzeichnis abgelegt).
Die bisherigen Diskussionen haben sich auf Zeichenketten als zu prüfende Werte konzentriert. Diese sind hauptsächlich die Sorgenkinder der sicheren Programmierung. Dennoch gibt es auch bezüglich der Verarbeitung von Zahlen Probleme. Nachfolgend sollen verschiedene Ansätze zur Prüfung dieser vorgestellt werden. Damit wird ebenfalls der Grundstein für die zum Schluss behandelte Prüfung von Symbolen in komplexen Zeichenketten gelegt werden.
Die meisten Programme müssen früher oder später einen Zahlenwert verarbeiten. Sei dies nun als Eingabe des Jahrgangs, einer Postleitzahl oder einer Telefonnummer. Handelt es sich um komplexe Zahlenkonstrukte, müssen diese grundsätzlich gleich wie eine Zeichenkette behandelt werden. Zum Beispiel dann, wenn ein Datum in der Schreibweise 11.02.1981 (dd.mm.YYYY) definiert wird. Schliesslich werden hier einzelne Werte (Tag, Monat, Jahr) durch den Punkt als Sonderzeichen voneinander getrennt.
Durch eine Funktion wie explode() könnten diese einzelnen Werte nun in ein eindimensionales Array $date gespeichert werden. So ist sodann in $date[0] der Tag (11), in $date[1] der Monat (02) und in $date[2] das Jahr (1981) abgelegt. Diese einzelnen Werte liessen sich nun weiterhin mit einer explizit für Zahlenwerte konstruierten Fassung von isinfected() prüfen.
function isinfected($notvalidated_input){
if($notvalidated_input < 1){
return true;
}elseif($notvalidated_input > 31){
return true;
}else{
return false;
}
}Sodann wird mit value_validation.php eine erste Fassung der Integervariante aufgezeigt, mit der fehlerhafte Werte bezüglich des Tags eines Monats erkannt werden können sollte. Auch hier wird im ersten an die Funktion übergebenen Parameter der zu prüfende Wert definiert. Er wird in $notvalidated_input und durch eine bedingte Anweisung kontrolliert.
Zuerst wird in Zeile 02 validiert, ob die Variable kleiner als 1 ist. Da ein Monat stets mit dem Tag 1 beginnt, ist ein Tag 0 oder ein negativer Tag -1 nicht zu erwarten. Wird ein solcher falscher Wert beobachtet, dieser wird in diesem Zusammenhang als Underflow bezeichnet, wird durch return der Wert true zurückgeliefert.
Konnte kein Underflow beobachtet werden, wird in einem zweiten Schritt mit elseif in Zeile 04 geprüft, ob der Wert grösser als 31 ist. Zwar gibt es den Februar, der entweder 28 oder 29 Tage hat sowie einige andere Monat, die lediglich 30 Tage haben. Es gibt jedoch keinen Monat, der mehr Tage als 31 hat. Würde eine solche Eingabe entgegengenommen worden sein, dies wäre ein Overflow, wird ebenfalls true zurückgegeben.
In allen anderen Fällen wird durch else in Zeile 06 der Wert false zurückgegeben. Die Eingabe ist demnach grösser als 0 und nicht grösser als 31. Sie ist damit im erwarteten Bereich und wird deshalb als legitim verstanden.
Je nach eingesetzter Programmiersprache oder genutztem Codierungsverfahren kann der gezeigte Programmcode jedoch überlistet werden, um dennoch unerwartete Eingaben als legitime Werte durchgehen zu lassen. Wird anstelle eines ganzzahligen Werts ein Sonderzeichen wie % übergeben, wird dies unter Umständen nicht kleiner als 1 und auch nicht grösser als 31 erkannt. Ist die Sprache sehr liberal im Umgang mit Datentypen, wird es sich auf die Rückgabe von false im finalen else-Block beschränken.
Eine gern genutzte Methode zur Verhinderung solcher Angriffe wird als Assertion, in der deutschsprachigen Literatur auch Zusicherung genannt, bezeichnet. Vor der Prüfung der Werte wird der für eben diese erforderliche Datentyp forciert. Hierzu kommt ein Type Casting, welches von den meisten professionellen Programmiersprachen bereitgestellt wird, zum Einsatz. In value_assertion.php gezeigten Erweiterung wird hierzu in Zeile 02 die Funktion settype() verwendet, um $notvalidated_input in jedem Fall in einen Integerwert umzuwandeln.
function isinfected($notvalidated_input){
settype($notvalidated_input, 'integer');
if($notvalidated_input < 1){
return true;
}elseif($notvalidated_input > 31){
return true;
}else{
return false;
}
}Jenachdem was für ein Mechanismus für die Typenumwandlung verwendet wird, muss mit anderen Resultaten gerechnet werden. So könnte settype() des gezeigten Beispiels aus Nicht-Zahlenwerten stets 0 generieren. Oder es könnte um eine Umwandlung in die ASCII- oder eine UNICODE-Form bemüht sein. Jenachdem wird also der weiteren Validierung gerecht geworden oder nicht. Dies hat sodann massgeblichen Einfluss auf die weitere Programmausführung.
Anstelle einer Typenumwandlung kann eine Typenprüfung genutzt werden, um etwaige Angriffe als solche zu erkennen. Die in value_typetest.php dokumentierten Erweiterung von isinfected() validiert nun als erstes mittels is_int(), ob es sich beim zu prüfendenden Objekt um einen Integerwert handelt (Zeile 02). Ist dies der Fall, wird die schon bekannte Werteprüfung in den Zeilen 03 bis 09 durchgeführt. Handelt es sich jedoch nicht um einen Integerwert, wird im else-Block der Wert true zurückgegeben (Zeilen 10-12):
function isinfected($notvalidated_input){
if(is_int($notvalidated_input)){
if($notvalidated_input < 1){
return true;
}elseif($notvalidated_input > 31){
return true;
}else{
return false;
}
}else{
return true;
}
}Das Prüfen von Zahlenwerten wird immerwieder erforderlich. Aus diesem Grund sollte auf eine generische Form der Funktion gesetzt werden. Hierbei erwartet die in value_function.php gezeigte Implementierung drei Argumente: (1) An erster Stelle wird noch immer die zu prüfende Variable übergeben. (2) An zweiter Stelle wird hingegen in $min der minimal erwartete Wert definiert. (3) Und an dritter Stelle wird zusätzlich in $max der maximal erwartete Wert angegeben. Durch Aufrufe wie isinfected($_GET['day'], 1, 31) können nun Tage des Monats und durch isinfected($_GET['month'], 1, 12) Monate selbst geprüft werden:
function isinfected($notvalidated_input, $min, $max){
if(is_int($notvalidated_input)){
if($notvalidated_input < $min){
return true;
}elseif($notvalidated_input > $max){
return true;
}else{
return false;
}
}else{
return true;
}
}In den meisten Fällen können die erwarteten Zeichen, die in einer Eingabe vorkommen können, eingeschränkt werden. Wie sich reine Zahlenwerte bezüglich ihrer Wertbereiche prüfen und einschränken lassen, wurde zuvor gezeigt. Doch auch Zeichenketten weisen in der Regel einen beschränkten zu erwartenden Zeichensatz auf.
Wird zum Beispiel in einem Formular der Name einer deutschen Automarke übergeben, sind ausschliesslich Buchstaben zu erwarten. Wird die Gross-/Kleinschreibung unterstützt, sind dies zwei Mal 24 Buchstaben des englischen Alphabets.
Bei ASCII (American Standard Code for Information Interchange) handelt es sich um eine 7-Bit-Zeichencodierung, welche durch klassische Computersysteme unterstützt wird. Die Zeichen umfassen das lateinische Alphabet in Gross- und Kleinschreibung, die zehn arabischen Ziffern sowie einige Satz- und Steuerzeichen. Sie werden dabei als eindeutiges Bitmuster abgelegt und lassen sich durch verschiedene Codierungen auswählen. So wird zum Beispiel dem Schriftzeichen A der dezimale Wert 65 bzw. der hexadezimale Wert 0x41 zugewiesen. Das Schriftzeichen B erhält 66 und 0x42 usw. Durch diese Zeichentabelle wird es möglich, dass eine einfache Eingrenzung auf einzelne Zeichenbereiche durchgesetzt werden kann:
function isinfected($notvalidated_input){
for($i=0; $i < strlen($notvalidated_input); $i++){
$symbol = ord(substr($notvalidated_input, $i, 1));
if($symbol < 65 || ($symbol > 90 && $symbol < 97) || $symbol > 123){
return true;
}
}
}Die Implementierung symbol_validation.php von isinfected() macht sich diese Eigenschaft der ASCII-Tabelle zunutze. Durch die in Zeile 02 eingeführte for-Schleife wird jedes Zeichen der Eingabe durchgegangen. In Zeile 03 wird sodann durch die Funktion substr() das einzelne Zeichen separiert und mittels der Funktion ord() in die dezimale Darstellung des ASCII-Werts umgewandelt. Dieser wird sodann in die Variable $symbol abgespeichert.
Danach wird durch eine komplexe bedingte Anweisung geprüft, ob sich das extrahierte Symbol auch im vorgegebenen Wertebereich befindet. Ist der dezimale Wert des Zeichens kleiner als 65 bzw. grösser als 90 und kleiner als 97 bzw. grösser als 123, so ist ein unerwünschtes Zeichen gegeben. Im Bereich 65 bis 90 finden sich nämlich Grossbuchstaben und im Bereich 97 bis 122 sind Kleinbuchstaben angesiedelt. Alles andere sind entweder Ziffern, Sonderzeichen oder Steuerzeichen, die allesamt unerwünscht sind. Wird ein solches gefunden, wird die Funktion mit dem Rückgabewert true verlassen.
Die Eingabe von Mercedes würde also keine Infektion feststellen, da hier ein Grossbuchstaben sowie Kleinbuchstaben des englischssprachigen Alphabets verwendet werden. Ebenso sähe es mit Porsche und Audi aus. Wird jedoch als Automarke Dürkopp ausgewählt, führt dies zu einem Fehler. Denn der zweite Buchstabe ist ein kleingeschriebener Umlaut (ü), der von ASCII so nicht unterstützt wird und deshalb auch nicht im definierten Zeichenbereich vorkommen kann. Hierzu müsste auf den erweiterten ANSI-Zeichensatz ausgewichen werden, der ebenso regionale Sonderzeichen, wie eben die genannten Umlaute, unterstützt.
Eine solche Prüfung der Wertbereiche eignet sich besonders für das Validieren von Werten mit eingeschränktem Zeichensatz (Zahlenwerten oder Buchstaben des englischen Alphabets). Das Analysieren von Sonderzeichen ist nicht wirklich möglich, da sich diese relativ ungeordnet über die Tabelle verteilen. Zwar können mit 60 bis 62 etwaige Vergleichsoperatoren <, = und > deklariert werden. Doch die arithmetischen Grundoperatoren Addition (43), Subtraktion (45), Multiplikation (42) und Division (47) sind zum Beispiel nicht gruppiert worden.
Müssen neben den gruppierten Zahlenwerten und dem einfachen Alphabet ebenso Sonderzeichen unterstützt werden, sollte auf eine leicht abgewandelte Prüfung gesetzt werden. Hierbei wird grundsätzlich das Prinzip der arraygesteuerten Whitelist mit der Prüfung der Zeichenwerte kombiniert, wie am Beispiel von chars_inarray.php gezeigt werden soll:
function isinfected($notvalidated_input){
$allowedchars = array('a', 'b', 'c');
for($i=0; $i < strlen($notvalidated_input); $i++){
$symbol = substr($notvalidated_input, $i, 1);
if(!in_array($symbol, $allowedchars)){
return true;
}
}
}
Zu Beginn wird im eindimensionalen Array $allowedchars sämtliche erlaubten Zeichen abgelegt (Zeile 02). In diesem Beispiel sind dies exemplarisch die Buchstaben a, b, und c. Es können aber auch komplexere und längere Definitionen, welche zum Beispiel zur Beschreibung eines HTML-Tags erforderlich wären, eingesetzt werden. Auch hier kann der Übersichtlichkeit halber eine Trennung zwischen Logik und Daten vorgenommen werden, indem die Whitelist in einer separaten Datei wie whitelist.txt geführt und durch eine Funktion wie file() eingelesen wird.
Danach folgt die bekannte Extraktion der einzelnen Zeichen der Eingabe. Dabei werden die einzelnen Symbole durch die Funktion substr() in die Variable $symbol abgelegt (Zeile 05). Durch die schon zuvor vorgestellte Funktion in_array() wird nun geprüft, ob das untersuchte Zeichen im Array enthalten ist. Ist es nicht im Array enthalten, dies wird durch den durch das Ausrufezeichen definierten _Not_-Operator dargestellt, wird eine Infektion identifiziert und deshalb true zurückgeliefert.
Hierbei wird auf eine Umwandlung zum dezimalen ASCII-Wert mit ord() verzichtet. Es wäre zwar auch möglich, müsste jedoch sowohl beim Zugriff auf das Allowed-Array als auch bei der Extraktion des Zeichens aus der Eingabe durchgeführt werden. Die Zeichen werden stattdessen ohne Umwandlung in direkter Weise verglichen, was sowohl einfacher zu administrieren als auch effizienter bei der Ausführung ist.
Die Schwierigkeit dieses Ansatzes besteht darin herauszufinden, welche Zeichen innerhalb einer Eingabe legitim sind. Handelt es sich um Zahlenwerte, wie zum Beispiel bei der Angabe des Geburtsjahres, ist der Fall klar: Im Array müssen die zehn Ziffern 0-9 abgelegt werden. Werden jedoch komplexere Zeichenketten genutzt, wie zum Beispiel die Angabe eines Namens, können ebenfalls regionale Sonderzeichen (z.B. é bei französischen Namen) zum Einsatz kommen.
Die Anwendung muss also während der Entwicklung einem umfangreichen Testing unterzogen werden, um all diese Spezialfälle zu erkennen und die Funktion damit trainieren zu können. In hochsicheren Umgebung kann dies am besten so gemacht werden, indem eine rudimentäre Implementierung mit den wichtigsten Zeichen in der Whitelist bereitgestellt wird. Jedes Mal, wenn jedoch eine Infektion identifiziert wird, da das geprüfte Zeichen in der Whitelist nicht enthalten ist, wird eine Meldung an den Entwickler geschickt. Dieser kann sodann sofort entscheiden, ob es sich wirklich um ein legitimes Symbol, dessen man sich noch nicht bewusst war, handelt und es entsprechend in die Liste der erlaubten Zeichen hinzufügen. Je länger dieser Benachrichtigungsprozess geführt wird, desto besser wird die Funktionsweise der Anwendung, ohne deren Sicherheit zu verringern.

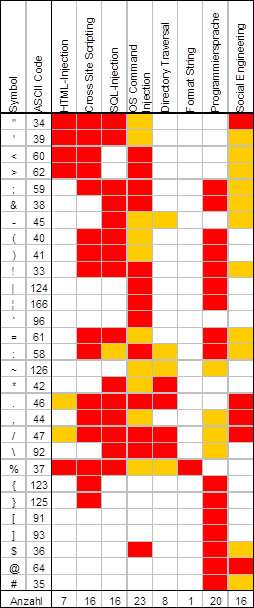
Der Einfachheit halber wird hier gerne mit dem Blacklisting-Ansatz gearbeitet. Dabei werden in das Array die nicht erlaubten Zeichen geschrieben. Die abgebildete Tabelle zeigt die jeweiligen Sonderzeichen und ihren Nutzen innerhalb einer technischen Attacke auf. Bei mit Rot markierten Feldern handelt es sich um wichtige und deshalb oft anzutreffende Angriffskatalysatoren. Die als Orange dargestellten Markierungen zeigen etwaige Erweiterungen oder als experimentell geltende Ansätze.
Zu Beginn wurde die absolute Prüfung von Eingaben vorgestellt: Entspricht eine Eingabe nicht dem Erwarteten, wird sie als infiziert betrachtet. Danach wurde eine dedizierte Prüfung einzelner Symbole besprochen: Findet sich in einer Eingabe ein unerwartetes Symbol, wird sie ebenfalls als infiziert verstanden.
Leider sind Eingabeüberprüfungen nicht immer in einer derartig einfachen Weise durchzusetzen. So gibt es Situationen, in denen Sonderzeichen erlaubt sind und andere Situationen, in denen sie eine Gefahr darstellen können. Zum Beispiel sind die Verhältniszeichen < (kleiner als) und > (grösser als) innerhalb mathematischer Betrachtungen durchaus legitim. So könnte in einem Foren-Posting zur Besprechung reeller Zahlen die erlaubte Zeichenkette 3.14 < 3.15 vorkommen.
Hingegen werden die genannten Sonderzeichen ebenfalls zur Definition von HTML-Tags, welche wiederum wichtiger Bestandteil von _Cross Site Scripting_-Attacken sein können, zum Einsatz kommen. Ist im Foren-Posting zum Beispiel die Zeichenkette <script>alert('xss');</script> enthalten, muss mit einem solchen Angriff gerechnet werden. Die Zeichen < und > erhalten dabei also aufgrund ihrer Meta-Funktionalität innerhalb von HTML eine gänzlich andere Bedeutung.
Durch die Prüfung von ganzen Zeichenketten soll es nun möglich werden, die Bedeutung derer zu erahnen und damit richtig zu reagieren. Betrachtet man sich die beiden Zeichenketten 3.14 < 3.15 (gutartig) und <script>alert('xss');</script> (bösartig), so fällt auf, dass die Sonderzeichen innerhalb einer speziellen Struktur zum Tragen kommen. Im erlaubten Fall wird das Zeichen eigenständig zwischen zwei Zahlenwerte gesetzt. Im unerwünschten Fall wird der Tag <script> hingegen durch die abgewandelte Darstellung </script> wieder abgeschlossen. Ohne diesen abschliessenden Tag würde der gesamte HTML-Tag nicht funktionieren. Wird also in einer Eingabe die reservierte Zeichenkette </ verwendet, muss es sich um einen abschliessenden HTML-Tag und damit um einen potentiellen Angriff handeln.
Wie gehabt soll nun in der speziellen Fassung von isinfected() im Array $disallowedstrings die unrlaubten Zeichenketten abgelegt werden (Zeile 02). Neben dem schon erklärten </ zur Identifikation von abschliessenden HTML-Tags soll zum Beispiel ebenfalls die Zeichenkette ../ sowie das Wort etc verboten werden. Ersteres ist das übliche Zeichen, welches für eine klassische Directory Traversal-Attacke eingespannt wird. Und zweiteres ist in Unix-Umgebungen das Standardverzeichnis für Konfigurationsdaten (z.B. Benutzerpasswörter), welches zusätzlich geschützt werden soll.
Die effektive Prüfung findet mit der neue vorgestellten Funktion strpos() statt. Diese erwartet zwei Parameter. Der erste ist der Ursprungswert, der analysiert werden soll. Der zweite sind die Zeichenketten, die gesucht werden sollen. Wird die gesuchte Zeichenkette in den Originaldaten gefunden, wird die Position des ersten Treffers zurückgegeben. Wird also die Zeichenkette Ruef in der Zeichenkette Marc Ruef gesucht, liefert strpos() den Wert 5 zurück. Schliesslich beginnt Ruef an der fünften Stelle. Wird hingegen Marc gesucht, liefert die Funktion den Wert 0 zurück, da dieser an der nullten Stelle gefunden wurde. Und wird Test gesucht, liefert die Funktion den boolschen Wert false zurück.
Ist die unerwünschte und gesuchte Zeichenkette in der Eingabe nicht enthalten, liefert sowohl strpos() als auch isinfected() den Wert false zurück. Konnte hingegen eine Infektion festgestellt werden, da die gesuchte Zeichenkette an einer bestimmten Position ausgemacht werden konnte, wird true zurückgegeben.
function isinfected($notvalidated_input){
$disallowedstrings = array('../', 'etc', 'script', '</');
if(strpos($notvalidated_input, $disallowedstrings) === false){
return false;
}else{
return true;
}
}Je nach Implementierung von strpos() kann sich das Verhalten natürlich ändern. Die hier gezeigte Fassung definiert die erste Stelle eines Hits mit dem Integerwert 0. Andere Implementierungen könnten mit dem Zählen bei 1 beginnen und beim Nichtauftreten der Zeichenkette den reservierten Wert 0 anstelle false zurückgeben. Es ist also sehr wichtig zu wissen, wie die genutzte Funktion arbeitet, um keine fehlerhaften Entscheidungen treffen zu lassen. Aus diesem Grund wird hier auch der typensichere Vergleich mit dem speziellen Operator === anstelle des simplen == durchgeführt. Würde letzterer eingesetzt werden, wäre auch das Auftreten an Position 0 von PHP als false gewertet und würde dann zu fehlerhaften Zulassungen infizierter Daten führen.

Dieser Ansatz scheint sehr komfortabel zu sein, da man in übersichtlicher Weise seine Blacklist pflegen und spezielle Situationen als solche Deklarieren kann. Tatsächlich handelt es sich hier jedoch um die unsicherste Methode überhaupt. In der Blacklist müssen schliesslich sämtliche gefährlichen Zeichenkombinationen abgespeichert werden. Es ist jedoch nahezu unmöglich alle Muster, wie sie in einem Angriff Verwendung finden können, zu kennen und adequat zu dokumentieren.
Im genannten Beispiel wird etc dokumentiert, um pausch alle Zugriffe auf das Systemverzeichnis von Unix-Systemen zu verhindern. Möchte man jedoch auch noch die anderen Standardverzeichnisse berücksichtigen, wächst die Blacklist explosionsartig an. Sodann müssten ebenfalls bin, home, lib, sbin, tmp und var hinzugefügt werden. Da voraussichtlich also sowieso alle Verzeichnisse aufgenommen werden wollen, sollte besser eine Whitelist (in diesem absoluten Fall wäre sie wohl leer) eingesetzt werden.
Desweiteren gibt es oftmals Abwandlungen bekannter Angriffsmuster, die zu gleichen oder vergleichbaren Resultaten führen können. Zwar wird im Beispiel die Zeichenkette script definiert, um klassisches Cross Site Scripting mit eben diesem Tag zu verhindern. Javascript lässt sich aber auch extern referenzieren, als Event-Handler eines bestehenden Tags nutzen (z.B. <a href="test.html" onMouseOver="alert('xss');">Link</a>) oder durch andere Schreibweisen (z.B. <ScRiPt>) oder gar Codierungen deklarieren.
Eingabeüberprüfungen sind zentraler Bestandteil der Sicherheit von Computersystemen. Durch die Validierung der an eine Software übergebenen Daten soll verhindert werden, dass diese den Anforderungen widersprechen und damit die korrekte Ausführung verhindern.
Dabei kann die Prüfung entweder mit einer Whitelist oder mit einer Blacklist umgesetzt werden. Auf einer Whitelist werden sämtliche Daten, welche legitim und deshalb zugelassen sind, aufgenommen. Nur wenn eine Eingabe diesem Kriterium, welches sich mit der Gästeliste einer Party vergleichen lässt, erfüllt, werden die Daten im regulären Zyklus weiterverarbeitet. Da dieser Ansatz sehr exakt arbeitet und keine Ausnahmen kennt, gilt er als der sicherste.
Jenachdem ist es jedoch nicht möglich von vornherein zu definieren, welche Daten erwartet sind. Zum Beispiel dann, wenn freie Textfelder (z.B. bei Foren-Posts) angeboten werden wollen. Dann lässt sich alternativ auf einen Blacklist-Ansatz setzen, bei dem verbotene Eingaben dokumentiert sind. Entspricht ein Datensatz einem solchen, wird der Zugriff verweigert. Bleibt eine Übereinstimmung aus, wird von einem legitimen Zugriff ausgegangen und die Ausführung weitergeführt. Das Problem hierbei ist, dass sich eine Blacklist nicht umfangreich und zeitnah verwalten lässt. Oftmals gibt es eine Vielzahl an abgewandelten Angriffsmustern (z.B. alternative Schreibweise oder Codierung), die durch eine starre Blacklist-Überprüfung nicht erkannt werden können.
Our experts will get in contact with you!

Marc Ruef

Marc Ruef

Marc Ruef

Marc Ruef
Our experts will get in contact with you!